;Resize,width=767;)

Chi usa frequentemente ChatGPT lo sa bene: non sempre le risposte che ci dà sono corrette. Capita spesso che il modello, con tono sicuro, dia informazioni che suonano plausibili ma in realtà sono sbagliate. Nel mondo dell’intelligenza artificiale questo fenomeno si chiama allucinazione, e riguarda tutti i modelli di linguaggio (non solo ChatGPT, ma anche Claude, Gemini, DeepSeek e altri).
Da tempo la ricerca accademica cerca di capire perché succeda e come ridurre il problema. All’inizio di settembre 2025, OpenAI ha pubblicato un’analisi in cui prova a spiegare le cause principali delle allucinazioni e a proporre alcune soluzioni.
Secondo lo studio, una parte del problema dipende dal modo in cui i modelli vengono valutati durante l’allenamento. Oggi, infatti, un modello viene “premiato” se prova a indovinare una risposta, anche quando non è certo che sia corretta. Così impara che è meglio inventare qualcosa piuttosto che ammettere di non sapere. Cambiando questo approccio, le allucinazioni potrebbero diminuire e i sistemi diventare più affidabili.
;Resize,width=578;)
Vediamo più nel dettaglio cosa sono le allucinazioni, cosa ha scoperto OpenAI e quali conseguenze sta portando.
Cosa sono le allucinazioni di ChatGPT
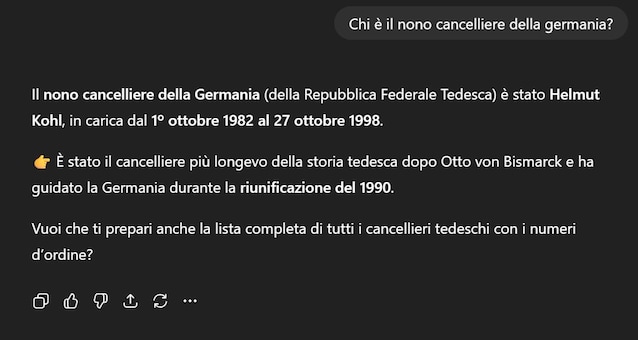
Nel contesto dell’intelligenza artificiale, un’allucinazione è una risposta che sembra corretta ma in realtà è inventata o priva di fondamento. Per esempio, abbiamo chiesto a ChatGPT: “Chi è il nono cancelliere della Germania?”. In tre tentativi diversi, da account diversi e in diversi momenti della giornata, il modello ha risposto: Willy Brandt, Helmut Kohl e Olaf Scholz. Solo quest’ultimo è corretto: le altre due risposte erano allucinazioni.
Le allucinazioni nascono perché i modelli di linguaggio sono stati progettati per generare testo coerente e naturale, non per sostituirsi a un motore di ricerca o fornire dati perfettamente accurati.
Perché avvengono le allucinazioni e come provare a mitigarle: lo studio
Nel suo articolo “Why language models hallucinate” (“Perchè i modelli di linguaggio hanno allucinazioni”), OpenAI spiega che il problema deriva dal modo in cui i modelli sono allenati e valutati: ad ora, un modello è stato considerato “migliore” se dava più risposte corrette. Di conseguenza, i modelli di linguaggio (LLM) vengono allenati a provare a dare una risposta, anche inventata, invece di ammettere di non saperla. Gli autori paragonano questo meccanismo a quello di studenti impreparati davanti ad una verifica a crocette: se non conoscono la risposta, preferiscono tirare a indovinare invece di lasciare la casella vuota, perché così hanno comunque una possibilità di guadagnare punti.
Ci sono poi altre due cause che portano gli LLM a sbagliare:
- La qualità dei dati: se nei testi usati per l’allenamento ci sono errori, il modello li ripeterà nelle risposte. È il principio del “garbage in, garbage out”: se inserisco spazzatura (dati errati), otterrò spazzatura (risposte sbagliate).
- I limiti della conoscenza: anche se i dati non contenessero nessun errore, non potrebbero comunque coprire tutto lo scibile delle conoscenze e delle risposte umane. Alcune domande non troveranno risposta nei dati, e il modello, avendo imparato che “è meglio dire qualcosa che ammettere l’ignoranza”, finirà per inventare.
Queste idee non sono del tutto nuove nel campo delle ricerca sulle allucinazioni, la novità introdotta da OpenAI è l’idea di cambiare il modo in cui valutiamo le risposte: penalizzare molto di più gli errori e premiare l’onestà del “non lo so”. In questo modo si punta a creare modelli più “umili”, mitigando così il problema delle allucinazioni.
Cosa si sta facendo per risolvere il problema
Già prima di questa ricerca, le aziende avevano sperimentato alcune soluzioni per ridurre le allucinazioni. Una delle più diffuse è l’uso di fonti esterne in tempo reale, come le ricerche sul web. Questa tecnica riduce le allucinazioni, anche se non le elimina del tutto.
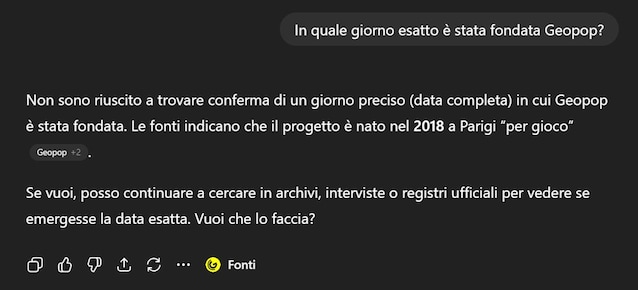
Con l’arrivo di GPT-5 i progressi sono diventati più evidenti. Oggi, di fronte a domande troppo specifiche, come “In quale giorno esatto è stata fondata Geopop?”, il modello ammette di non conoscere la risposta, cosa impensabile con le versioni precedenti.
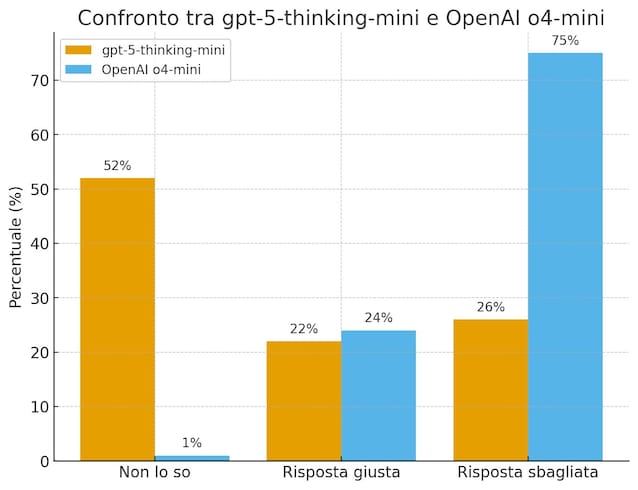
Secondo i dati di OpenAI, quando hanno testato il nuovo modello gpt-5-thinking-mini (la versione più "piccola" e meno potente di GPT-5) su un dataset creato apposta per misurare l'abilità di fare fact-checking, ha ammesso di non sapere nel 52% dei casi (contro l’1% della versione precedente) e ha commesso meno errori (26% contro 75%). La percentuale di risposte esatte è stata leggermente più bassa (22% contro 24%), ma la qualità complessiva è migliorata: meglio un modello che ammette i propri limiti, piuttosto che uno che sbaglia con sicurezza.
Un altro fronte di ricerca su cui si sta impegnando OpenAI riguarda il linguaggio con cui l’AI comunica l’incertezza. Nel nostro esempio iniziale, sarebbe stato molto diverso se ChatGPT avesse risposto: “Forse il nono cancelliere potrebbe essere Kohl” invece che darci con grande sicurezza la risposta sbagliata. Una risposta del genere avrebbe reso più evidente che non si trattava di un dato certo.
Resta comunque ancora aperto un problema molto grosso: più le risposte sono lunghe e strutturate, più aumenta il rischio di allucinazioni. Questo problema è molto più difficile da risolvere e la soluzione proposta da OpenAI non è sufficiente. Questo studio, però, è un segnale positivo nella direzione giusta: è evidente che OpenAI stia lavorando per ottenere un'AI più affidabile. E, nel frattempo, noi utenti possiamo continuare ad utilizzarla con spirito critico, controllando sempre le risposte che otteniamo.
;Resize,width=767;)
;Resize,width=727;)

;Resize,width=727;)

;Resize,width=727;)

